
Spectra Assure Free Trial
Get your 14-day free trial of Spectra Assure for Software Supply Chain Security
Get Free TrialMore about Spectra Assure Free Trial
Machine learning (ML) is commonly used for malware detection alongside traditional approaches, such as signature-based detections and heuristics. The advantages of machine learning over traditional approaches are that it is much more capable of detecting novel (not previously seen) malware and is better suited to keep pace with malware evolution and large volumes of data. However, machine learning has its weaknesses.
It is known that ML models have issues with adversarial examples — inputs to ML models designed by an attacker to cause the model to make a mistake. The inputs can be slightly altered but dramatically change a model’s response despite being unnoticeable to humans. Adversarial examples can produce strange and unwanted behaviors, and allow attackers to evade malicious file detection. Given that adversarial machine learning exploits software weaknesses, it should be addressed like any other software vulnerability.
The problem of adversarial examples can be easily understood through the relatively simple computer vision task of image classification. Figure 1 shows an adversarial example created by adding what appears to be noise to an image of a panda, which caused the ML classifier misclassification.
-497x186.png&w=1080&q=75)
Figure 1. Adversarial example from Explaining and Harnessing Adversarial Examples
Get White Paper: How the Rise of AI Will Impact Software Supply Chain Security
In the context of malware detection, adversarial examples are malicious samples modified in some way to bypass ML detections. In particular, Windows Portable Executable (PE) files can be modified in various ways; for example, by appending bytes and strings from benign files to the overlay and newly created sections.
When generating PE adversarial samples, it is important to maintain the functionality of the program without compromising its execution. This can be achieved by using functionality-preserving modifications which can be categorized as structural or behavioral.
Structural modifications exploit ambiguities of the PE file format used to store programs on disk, and affect only the PE format without altering its behavior. They include perturbing header fields, modifying bytes in DOS header and stub, filling slack space inserted by the compiler, injecting unused import functions, injecting new sections, injecting bytes into padding, and creating additional space by shifting the content forward. The majority of structural modifications are related to injecting adversarial content into PE files. Behavioral modifications, on the other hand, change the program behavior and execution traces while preserving the intended functionality of the PE program. Those modifications are beyond the scope of this blog.
Many different algorithms for generating PE adversarial samples by selecting and applying modifications have been proposed in scientific papers. They use concepts such as generative adversarial networks, reinforcement learning, and genetic algorithms. But these algorithms are iterative and not easily applicable, requiring considerable time to generate just one adversarial sample.
ML models need to be hardened against adversarial samples before they are put into production. The most explored method for creating more resilient models is adversarial training. Adversarial training is performed by including adversarial samples with appropriate labels in the training data set, allowing the models to see them during training and classify them better.
Another option to improve robustness is using ensembles of ML models to create stronger predictions by combining the results of diverse models. Ensembles can be more resilient to attacks because an attack that bypasses one model does not necessarily bypass all other models in the ensemble. However, the disadvantage of using ensembles is an increase in resources and time needed for evaluation.
A third option to make ML models more robust against adversaries is to use knowledge distillation, where a student neural network can be trained with an ensemble teacher and eliminate the cost of ensemble evaluation. Although all these methods make it harder for an attacker to evade detection, they are not universal for detecting adversarial samples.
ReversingLabs ML solutions are integrated within static analysis and mainly based on human-readable indicators that summarize the object's behavior. Our static analysis performs quick and detailed file analysis without executing the file, while indicators facilitate file analysis and offer explainability and understanding of why the file was detected. In addition to indicators, other hand-crafted features are used depending on specific file types.

Figure 2. ReversingLabs A1000 - Indicators view: Explainable classification with transparent and relevant indicators
We enrich our training data set with adversarial and perturbed samples to produce more resilient ML models for PE malware detection. Since it is not easy to collect adversarial samples for PE in the wild, we had to generate them in some way.
Everyone who has played around with modifying PE files knows how difficult it is to generate functionality-preserving PE samples that can be parsed and executed after the modifications are applied. To avoid complications with changing and rebuilding PE files, we decided to focus on making modifications directly in the feature vector space instead of modifying PE files. That enabled us to produce adversarial samples during training in real-time, and to create multiple adversarial samples for all samples in our training data set.
It is important to emphasize that the ability to make modifications in the feature vector space allows the defender to make the models robust to theoretical attacks without the burden of creating functional adversarial samples.
We have selected a subset of features from the input feature vector to apply modifications to. The subset includes features related to the DOS header, the PE header, and indicators that appear only in benign files. Those parts of the input feature vector are descriptive, but the malware detection model should be resilient to changes to those features, since they do not contain malicious behavior.
-1358x364.webp&w=3840&q=75)
Figure 3. Representation of a PE file in the feature vector space
Features associated with DOS and PE headers are mainly checks for consistency with the PE file format specifications, and are more often triggered within malicious files. Indicators from benign files can be triggered within the entire PE file (including strings, imports, exports, sections, content, and overlay), so adding them in the feature vector space corresponds to injecting benign content into the PE file. We will refer to these two groups of features as "header" and "indicator" features.
To evaluate how modifications of header and indicator features affect our deep learning model, we selected millions of benign and malicious samples for testing. When we tested the model on samples with added perturbations of indicator features, we observed that it pushed the model’s predictions toward the benign class. Testing on samples with added perturbations of header features, we noticed that it pushed the model’s predictions toward the malicious class. These results are justified by the fact that indicator features appear only in benign files, and header features mainly in malicious files.
This showed that perturbations of input features can lead to a drop in the detection of malicious samples and increase the number of false positive detections. To overcome these unwanted behaviors, we adopted adversarial training and included perturbations of the indicator and header features during resilient model training, and randomly applied perturbations to the training data.
To measure whether the model is resilient to modifications, we compared model predictions on unmodified test samples to model predictions on test samples with randomly added perturbations. A model is considered more robust if fewer predictions are changed, and ideally a robust model should have the same predictions for original and adversarial samples.
Figure 4 shows the percentage of predictions that changed from malware to benign for the original and for the resilient model after randomly adding up to 10 perturbations of indicator and header features to test samples. The percentage of changed predictions is much lower for the resilient model in all three cases, i.e. when only the indicator features, only the header features, and both groups of features are modified. This shows that the resilient model is much more robust to perturbations of the input features, and has significantly reduced the drop in the number of detections of malicious adversarial samples compared to the original model.
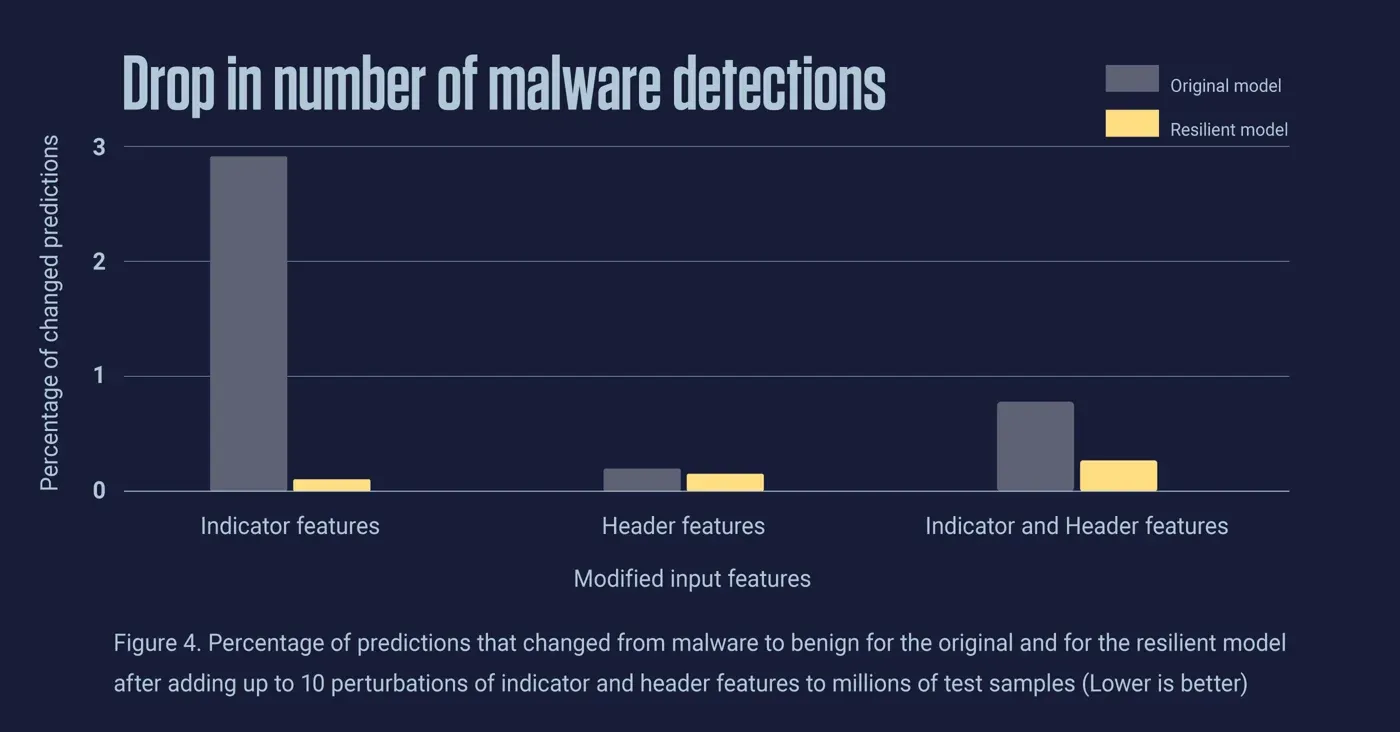
Figure 4. Percentage of predictions that changed from malware to benign for the original and for the resilient model after adding up to 10 perturbations of indicator and header features to millions of test samples (Lower is better)
Furthermore, Figure 5 shows that the resilient model also has a much lower percentage of predictions that changed from "benign" to "malicious" after adding perturbations of the input features. In other words, it successfully reduced the number of false positive detections of adversarial samples compared to the original model.

Figure 5. Percentage of predictions that changed from benign to malware for the original and for the resilient model after adding up to 10 perturbations of indicator and header features to millions of test samples (Lower is better)
The percentage of all changed predictions is almost reduced to zero for the resilient model, which is indeed a significant improvement in classification accuracy on adversarial samples. It is also important to mention that the resilient model has no drop in overall performance on unmodified samples compared to the original model.
ML models play an important role in cybersecurity despite being vulnerable to adversarial examples, and they must be made more resilient to adversarial attacks. As the attacks become more sophisticated, it is imperative to harden ML models and reduce the adversary’s ability to evade detection systems.
We hardened our ML models for PE malware detection by randomly applying modifications to the headers and injecting content from benign files during model training. This led to improved model generalization and reduced overfitting to the subset of features that are now less relevant in making final classification decisions.
From now on, all ML models for PE malware detection will be hardened in this way. Since they are integrated into our advanced static decomposition engine, which is the core of all our products, our users will be more protected from existing and future adversarial attacks.
Learn more about explainable machine learning and how it can detect ransomware threats.